Building an R Package and Web Application to Interact Within a Digital Ecosystem for Literary Studies

Ivan Pozdniakov is a researcher with a background on x. He applied for a TNA fellowship at the University of Potsdam in Germany to work on developing and improving web application using Shiny and R package {rdracor} for easier and more straightforward interaction with DraCor.
Drama Corpora Project (DraCor) is a large and growing ecosystem for Drama analysis. DraCor is a realization of the Programmable Corpora concept and provides an access to data for plays in several drama corpora. Every drama is encoded using TEI that helps to analyze different plays and the whole corpora by access to the project’s API.
Ivan’s project involved adding new features, refactoring the existing code, updating code to the current version of API, writing documentation, implementing unit-tests, writing tutorials, and updating UI (for the Shiny web application).
What was the aim of your TNA fellowship?
My stay at the University of Potsdam, Germany from April 15th, 2022 to June 14th, 2022 was dedicated to the development of “rdracor”, a package in the programming language R, that could be used to analyze the literary data provided by the Drama Corpora Project (DraCor). DraCor is a prototype of the Programmable Corpora concept that is explored within the CLS Infra Project in Work Package 7 led by the University of Potsdam and provides data on theater plays in several European languages. Every play is encoded using TEI that helps to analyze different plays and the whole corpora by access to the project’s API.
I am excited by insights given by the distant reading approach and I believe that providing a complex but easy–to–use infrastructure for computational research in Literary Studies will not only make it less challenging and faster but also will lead to new hypotheses and ways to test them. Thus my particular interest was to develop a package that could be used by the R community within CLS in native way to the programming language and build on commonly used data structures, like datatables.
During my stay in Potsdam, in several meetings with my TNA mentor, Prof. Peer Trilcke and team members of CLS INFRA project and the Potsdam Network for Digital Humanities we went through the functions provided by the DraCor API and discussed which of them needed to be represented in the package. I then updated some of the legacy code to the current version of API, but also focused on making the code more independent of possible future changes of the API by implementing a generic function that could send requests not only to the current production version of the platform, but also to local instances running in a Docker container.
What were your first results coming out from your fellowship?
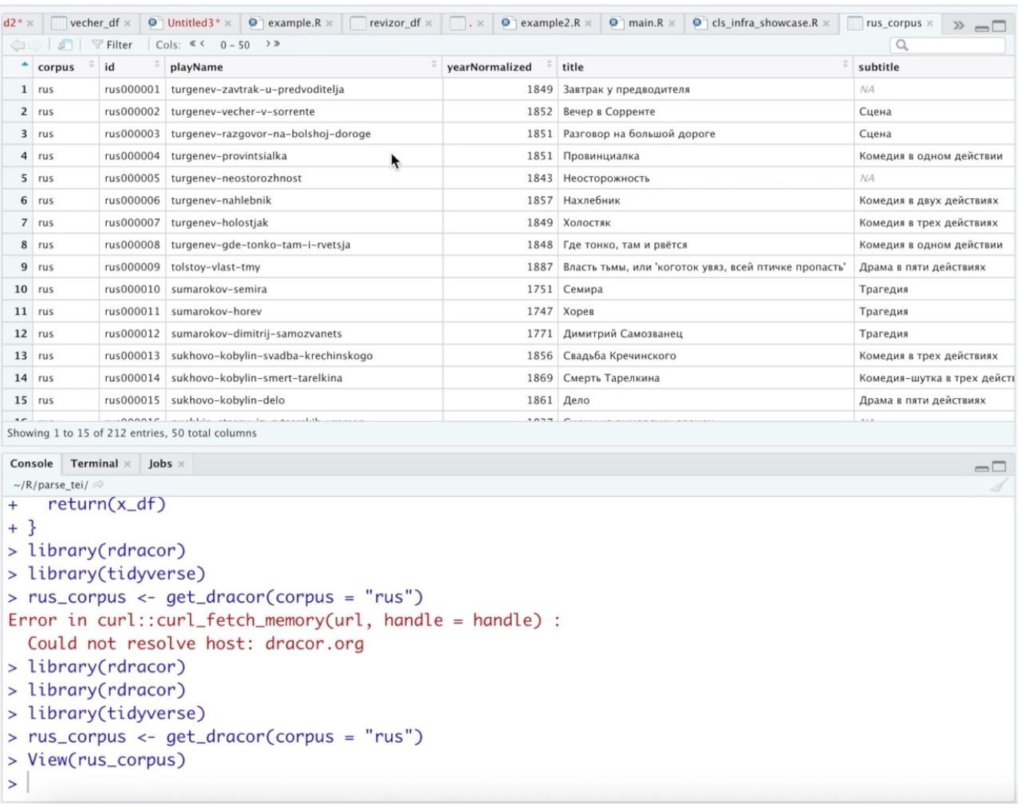
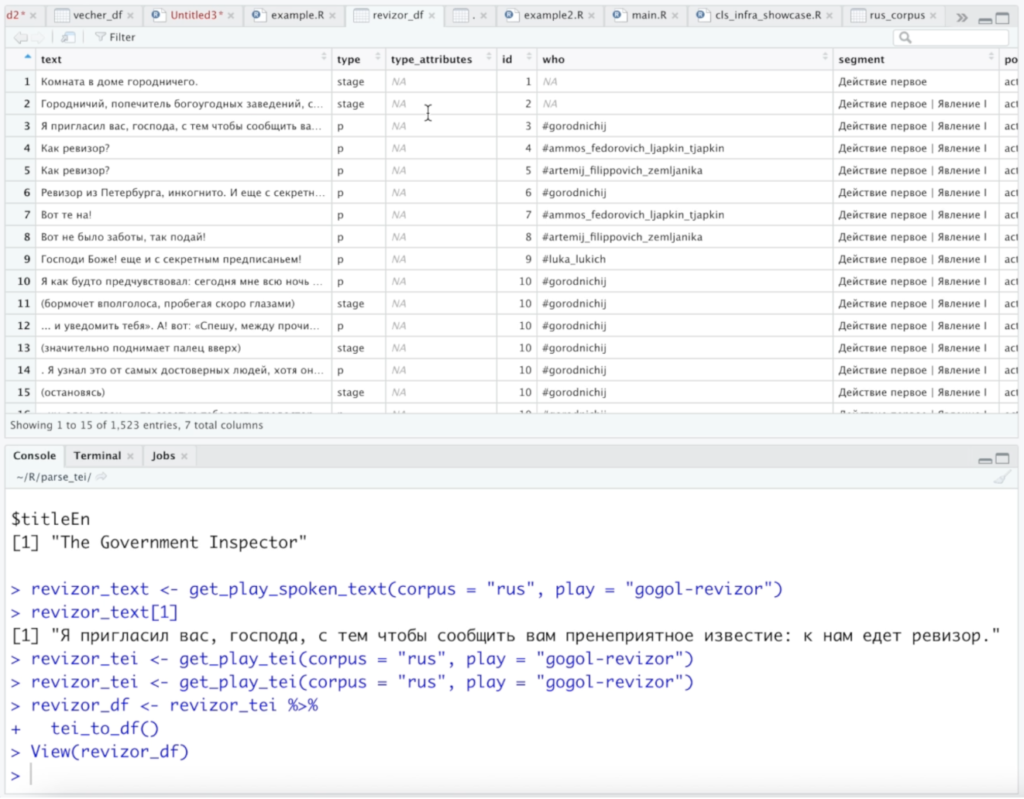
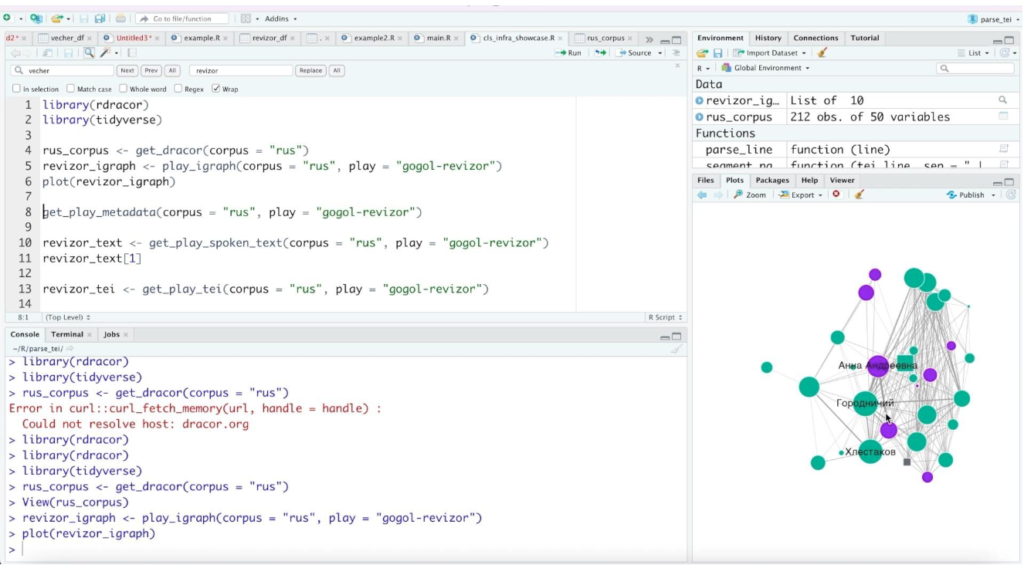
‘get_dracor’ command: