Project outputs
Table of contents
Deliverables
TNA Fellowships
Miscellaneous
D6.1: Inventory of existing data sources and formats
This deliverable summarises the work done to compile a comprehensive overview of the landscape of literary corpora and sources currently available.
It describes the methodological approach of the work group and analyses the various challenges encountered in the effort to collect information about these resources and consolidate them into a structured form.
Based on an initial inventory of 86 corpora or corpus sets, the report exemplifies their wide variety with respect to structure, context and purpose, and consequently the differing modes of provisioning.
It also proposes a technological path towards making this information searchable via a central discovery catalogue by discussing principal design decisions regarding the data model and the technology stack needed for such a task.

D2.2 Final Report on Dissemination, Communication and Exploitation
This communication and dissemination final report assesses how and where the results of CLS INFRA were disseminated and valorised across all appropriate user communities. CLS INFRA has succeed in creating and training a global network of scholars and practitioners of CLS methods and the WP2 Communication team has been instrumental in broadening the community and deepening its engagement.
Overall, this report demonstrates the success of the CLS INFRA project communications in achieving objectives, responding to challenging and changing pressures in the field, and completing tasks above and beyond those planned to reach our goals.

D3.4: Position papers and pilot studies on emerging trends in CLS
Computational Literary Studies is an area of research which, like its disciplinary context of the Digital Humanities, has a very high affinity with innovation and experimentation and is usually quick to adopt and adapt recent developments in areas of research like Natural Language Processing and Machine Learning. As a consequence, it is a field that is highly dynamic and it is important to monitor not just well-established best practices, tools and requirements (as we have done in previous work within CLS INFRA, notably in Schöch et al. 2023), but also to investigate, discuss and make visible emerging trends in the field which are likely to influence the field, its practices and needs, in the near future.
Documenting three such emerging trends has been the objective of this part of our work within CLS INFRA. We have done this in several different ways: Using both the survey article format to provide overviews of current trends, as well as pilot studies as well as short papers providing background, context and explanations for these pilot studies.

Explainer: Deliverables 8.3-8.5: Applying NLP tools (REX, NER, ABSA)
In this video Tess Dejaghere of the University of Ghent Center for Digital Humanities explains the work done for and the outputs of Deliverable 8.3: Report on Applied NLP: Named Entity Recognition (NER), Deliverable 8.4: NLP: Relational Extraction (REX) and Deliverable 8.5: NLP: Sentiment Analysis.
D8.5: Report on Applied NLP Sentiment Analysis
This report documents the continued work of Work Package 8 to increase the ease of access and application to NLP tools, including for less-well-resourced languages, as well as their standardization, specifically involving Sentiment Analysis (SA). SA, a widely used text mining method for categorizing textual entities as positive, neutral, or negative, has faced criticism in literary studies for its limitations. Scholars argue that the rigid polarity scheme of contemporary SA tools is ill-suited to the nuanced and complex interpretive needs of humanist research. In response to the inherent limitations of traditional SA tools in CLS, Aspect-Based Sentiment Analysis (ABSA) has emerged as a promising alternative. Unlike conventional SA systems that assign a single polarity label at the document, paragraph, or sentence level, ABSA operates at a finer level of granularity by focusing on specific aspects within the text.
While presenting ABSA as a panacea would be an overstatement, exploring new methodologies to assess the applicability of NLP in Digital Humanities (DH) practice is essential. The work done for this report aims to respond to calls for an exploratory approach in NLP-infused literary analysis methodologies. Thus we created notebooks for three workflows:
- A lexicon- and rule-based approach was created for aspect extraction
- Opinion word identification, and
- sentiment analysis based on the extracted opinion words.
Jupyter Notebooks
The Jupyter notebooks developed by Work Package 8 demystify pipelines and inspire users to re-use, adapt and improve these methodologies for their own use-cases. Click here for documentation, installation, and user guides.


D8.4: Report on NLP Relational Extraction (REX)
This report documents the continued work of Work Package 8 to increase the ease of access and application to NLP tools, including for less-well-resourced languages, as well as their standardization, specifically involving Relational Extraction (REX). REX was
developed as a set of techniques from NLP and information retrieval, traditionally implementing rule based systems to infer relations between entities. In WP8 we aimed to further refine computational relational extraction by identifying co-occurrences between named entities at a number of different levels: sentence, correspondence (i.e. sender –reciever), and between/across documents in a corpus. To implement this task we employ a generative AI approach using a Retrieval-Augmented Generation (RAG) system to identify relations.
By addressing the challenges of static knowledge and hallucinations inherent in Large Language Models (LLMs), this approach offers a promising pathway for integrating advanced AI techniques into the Digital Humanities, fostering more accurate and insightful analyses and uncovering the application range of LLMs.
Jupyter Notebooks
The Jupyter notebooks developed by Work Package 8 demystify pipelines and inspire users to re-use, adapt and improve these methodologies for their own use-cases. Click here for documentation, installation, and user guides.

D8.3: Report on Applied NLP Named Entity Recognition
This report documents the work of Work Package 8 to increase the ease of access and application to NLP tools, including for less-well-resourced languages, as well as their standardization, specifically involving NER: Named Entity Recognition. The report is organized as follows: a generation explanation of named entity recognition tasks, technical boundaries, challenges for literary scholar (and or those working with unstructured texts) and thus proposed tools for these tasks. This includes machine learning pipeline for automatically extracting pre-defined mentions of known objects, such as people, places or organizations to generative AI solutions and in multiple languages appliacle to a wide set of scholars. These tools integrate work in both WP 6 and 7 which facilitates integration of the pipeline from data preparation, programmable corpora, to analysis and back.
Jupyter Notebooks
The Jupyter notebooks developed by Work Package 8 demystify pipelines and inspire users to re-use, adapt and improve these methodologies for their own use-cases. Click here for documentation, installation, and user guides.

D6.2: CLSCor Catalogue- Transformation toolbox and ingest and processing workflow
The CLSCor catalogue is an exploration platform gathering information about literary corpora, as well as applicable tools. It was created in the context of CLS INFRA adressing existing fragmentation and heterogeneity of resources in the domain by building a common infrastructure for Computational Literary Studies. The metadata on both corpora and tools collected during the project, was harmonised, consolidated, and mapped to the specifically designed CLSCor data model and its corresponding vocabularies.
This deliverable report describes the work in task 6.2 of the CLS INFRA project, with the goal to combat the heterogeneity and incoherence of the CLS ecosystem and to improve the interoperability between data and tools, through a special toolkit, the Transformation Toolbox, providing harmonised means for converting data between formats.
To this end, a novel technical concept has been proposed, VELD (Versioned Executable Logic and Data) – a generic mechanism to harmonise description of and improve interoperability between heterogeneous resources and to construct processing pipelines combining heterogeneous tools using widely adopted technologies, which at the same time ensures reproducibility of the workflows.
This mechanism was complemented with a comprehensive overview of resources, tools and data, available in the domain using a common unifying data model.
Taken together these results represent a significant contribution to the consolidation of the CLS ecosystem.


CLS INFRA TNA Fellows Kathryn Laing & Geraldine Brassil
In this video, CLS INFRA TNA Fellows Kathryn Laing & Geraldine Brassil speak about the project: ‘Enhancing the Irish Women’s Writing Network 1880-1920 Website: Data Capture, Digitisation, Visualisation’ Affiliation: Department of English Language and Literature, Mary Immaculate College, Limerick, Ireland. Host: TCDH: The Trier Center for Digital Humanities.
Read the blogpost written by Laing and Brassil here: https://irishwomenswritingnetwork.com – Irish Women’s Writing (1880-1920) Network
CLS INFRA TNA Fellow Maria-Corina Dimitru
In this video, CLS INFRA TNA Fellow Maria-Corina Dimitru discusses the TNA Fellowship project: “Parametrization Guidelines in StyloR for the Romanian Language“.
Metadata Desiderata for Literary Corpora
Metadata Desiderata for Literary Corpora: A survey for starting a conversation between literary studies, libraries and research data repositories.
The poster presents the highlights of the results of a survey on the categories that literary scholars find most important when composing literary corpora or collections. The survey was carried out by the German NFDI consortium Text+, the DFG priority program (SPP 2207) Computational Literary Studies and the European project CLS Infra. All projects are strongly linked to both, literary studies and research infrastructures.
Calvo Tello, José, Nanette Rißler-Pipka, Sally Chambers, Philippe Genêt, and Patrick Helling. “Metadata Desiderata for Literary Corpora: A Survey for Starting a Conversation between Literary Studies, Libraries and Research Data Repositories.,” May 16, 2024. https://doi.org/10.5281/ZENODO.11202131.

D3.5: User User needs beyond academic research for Computational Literary Analysis
In spite of decades of studies and manifestos arguing for the ‘use’ of the humanities for various purposes, from their capacity to form citizens (Nussbaum, 1998, 2010) through to more specific appeals to their potential to improve technology development (Madsbjerg, 2017), the idea of an ‘applied humanities’ has yet to fully take explicit hold within our training and research paradigms. In spite of this, however, appeals to the humanities-relevant power of narrative and storytelling seem ever more present in new journalism, brand narratives, and even narrative economics (Shiller, 2019). For this reason, we reviewed literature on applications of fiction, literary studies, or CLS outside of the academy to identify professionals who could benefit from this CLS infrastructure.

CLS INFRA TNA Fellow Vladimir Polomac
In this video, CLS INFRA TNA Fellow Vladimir Polomac discusses the TNA Fellowship project: “Universal Dependencies for Old Serbian and Serbian Church Slavonic: Creating a training data set for lemmatization and morphosyntactic annotation using UDPipe“.
D5.3: Toolkit for Data Sharing
There are many choices to make over your Research Data’s Life Cycle. This wiki covers good practices in the context of CLS corpora and data including:
- planning and designing data
- creating and collecting data
- preparing and enriching data
- preserving and publishing data
- reusing data

CLS INFRA TNA Fellow Floriana Ceresato
TNA presentation: Floriana Ceresato in ‘DH and Medieval Romance Philology: Two Case Studies’: Seminar at the University of Galway, 3 July 2024.
CLS INFRA TNA Fellow Simone Marcenaro
In this video, CLS INFRA TNA Fellow Simone Marcenaro discusses the TNA Fellowship project: “Harmonizing Artistry: exploring the collaboration between AI and human expertise in translating Galician-Portuguese Troubadour poetry (phase one)“.
TNA presentation: Simone Marcenaro in ‘DH and Medieval Romance Philology: Two Case Studies’: Seminar at the University of Galway, 3 July 2024.
CLS INFRA TNA Fellow Lucas Van der Deijl
In this video, CLS INFRA TNA Fellow Lucas Van der Deijl discusses the TNA Fellowship project: “Deploying DutchDraCor: integrating 150 early modern Dutch plays (1550-1700) into the infrastructure of the Drama Corpora Project (DraCor)“.
CLS INFRA TNA Fellow Byungjun Kim
In this video, CLS INFRA TNA Fellow Byungjun Kim discusses the TNA Fellowship project: “Integrative Approaches in Computational Literary Studies and Global Knowledge Structures“.
CLS INFRA TNA Fellow Natalie Kamovnikova
In this video, CLS INFRA TNA Fellow Natalie Kamovnikova discusses her experience as a TNA Fellow on her project: “Corpus building classification and preservation of contemporary anti-war poetry in the context of its vulnerability”.
CLS INFRA TNA Fellow Julia Neugarten
In this video, CLS INFRA TNA Fellow Julia Neugarten discusses her experience as a TNA Fellow on her project: “Catching Feelings: Aspect-Based Sentiment Analysis for Fanfiction about Greek Myth”
Here CLS INFRA TNA Fellow Julia Neugarten gives an in-depth presentation on her project “Catching Feelings: Aspect-Based Sentiment Analysis for Fanfiction about Greek Myth”. Julia and a team of researchers at GhentCDH & Lt3 are mapping the ways fanfiction-readers evaluate the stories they read in the Greek mythology fandom on popular fanfiction-website “Archive of Our Own”. Using aspect-based sentiment analysis (ABSA), Julia and her colleagues examine how several aspects of fanfiction about Greek myth are evaluated by commenters. In this presentation, Julia will report on the processes of data collection and annotation for the project, introduce the different aspects, describe the pipeline for aspect-based sentiment analysis and present some preliminary results. Julia Neugarten is currently at General Cultural Sciences at Radboud University Nijmegen within the Anchoring Innovation project.
- Ghent University Centre for Digital Humanities: https://www.ghentcdh.ugent.be
- LT3: https://lt3.ugent.be
- Anchoring Innovation: https://www.ru.nl/en/research/research-projects/anchoring-innovation
CLS INFRA TNA Fellow Radim Hladík
In this video, CLS INFRA TNA Fellow Radim Hladík discusses a TNA Fellowship project: “A Sprint for FAIRer Data: development of features for data exchange and publication in research software for qualitative data analysis“
D8.2: Report and prototypes for annotation as enrichment
Annotations (or textual encoding) can serve many purposes depending on the task at hand. In literary studies specifically, annotation is implemented for a number of reasons: 1) for reference for a scholar’s own use or for others (i.e. scholarly edition), 2) to share notes and ideas with others, 3) linguistic markups and so forth. These annotations are then used in many different ways including used as a source for scholarly editions to qualitative and quantitative pattern tracing that could include a number of methods from discourse or theme identification to the use of NLP such as identification of named entities.
In this deliverable we report on the development of a number of tools that aim to fill the gap between TEI & NLP tool use. This includes TEITOK, TXM, PoetryLab API, Rantanplan, and Alberti-stanzas.
Read the full report here:
CLS INFRA TNA Fellow Botond Szemes
In this video, CLS INFRA TNA Fellow Botond Szemes speaks about the project: ‘New Metrics for Computational Drama Analysis’
TNA Mini-Conference, UNED
Three CLS INFRA TNA Fellows at LINHD-UNED in Madrid took part in an online mini-conference on 24 April, 2024. Each presented on their research and discussed their plans with each other.
- Jyothi Justin, Digital Humanities and Publishing Studies Research Group, IIT Indore. Project title: SEEING THE UNSEEN: LOCATING THE WOMEN OF INDEPENDENT
INDIA’S UNHEARD DALIT MASSACRES - Eduardo Fernández Guerrero, European University Institute: DISTANT READING OF EARLY MODERN PROPHECIES ACROSS EUROPE: CORPUS FORMATION AND TESTING
- Marko Milosev, Central European University, Vienna, Austria: WORDS TO ACTION: HOW AND IF IDEOLOGY TRANSLATES TO
VIOLENCE IN THE CASE OF INTERWAR FASCISTS
ORGANISATIONS - Bonus video: all three discuss their experience of being a CLS INFRA TNA Fellow

D7.3: On Versioning Living and Programmable Corpora
Digital corpora, which are proving more and more to be the most important epistemic objects of Computational Literary Studies (CLS), are by no means always static objects. On the contrary, it is becoming increasingly clear that the digitisation of our cultural heritage needs to be understood as an ongoing process, which also implies that a number of the epistemic objects of CLS must be conceptualized as genuinely dynamic. We address this specific quality of some epistemic objects of the CLS by speaking of “living corpora”. Where corpora — as the data of CLS — are also conceptually combined with code (e.g. in the form of an API) to form more complex research artifacts, we speak of “programmable corpora”, as described in detail in CLS INFRA Deliverable D7.1 “On Programmable Corpora”.
However, both living and programmable corpora usually face a considerable problem when discussed with regard to the reproducibility of research. This report considers possible solutions for the stabilization of living and programmable corpora and thus shows ways of making them available for reproducing research in a sustainable and long-term manner.
Read the full report here:
CLS INFRA TNA Fellow Agnieszka Szulińska
In this video, CLS INFRA TNA Fellow Agnieszka Szulińska discusses her TNA Fellowship project: “Behind the scenes. Integrating TEI Panorama of Polish drama data into DraCor Programmable Corpora”
D7.2 API Libraries for R and Python for DraCor
Accessing literary corpora via application programming interfaces (APIs) proves to be a promising approach in the development of an infrastructural ecosystem for Computational Literary Studies (CLS). The use of APIs is further facilitated by so called “API wrappers”, i.e. programming libraries that simplify working with the API directly from within a programming language. For the system DraCor (“Drama Corpora Platform”), which is being developed as a prototype for Programmable Corpora within the framework of CLS INRFA, and for its DraCor API, such libraries were developed in the two widely used programming languages R and Python and published on the corresponding platforms: “rdracor” was published on the platform CRAN, “pydracor” on the platform PyPiy.
D3.3 Showcases for the Application of CLS Methods and Tools
Are you an academic or non-academic literary researcher, linguist, or educator interested in how digital tools and methods can expand your knowledge? A scholar in the Digital Humanities field interested in CLS tools and methods?
The four showcases brought together in this deliverable illustrate, in a concrete, visual and interactive way, how some of the key methods in CLS work when they are applied to collections of literary texts. They are demonstrations, with a relatively low threshold for access, of how tools and datasets as elements of an integrated infrastructure such as the one developed in CLS INFRA, can be used in research.
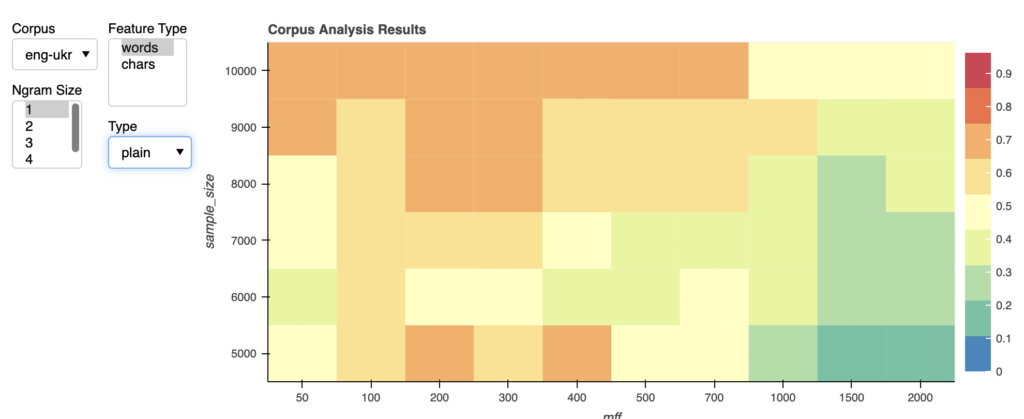
Multilingual Stylometry Showcase
- Designed for: scholars and students, linguists
- Topics: the intersection of language, corpus composition, and stylometric methods of authorship attribution.
- Dataset: a curated dataset from the ELTeC corpus, including texts in English, French, Hungarian, and Ukrainian, each translated to facilitate comparative analysis across languages.
By presenting stylometric analysis through interactive heatmaps, our tool invites users to engage directly with the data, exploring how linguistic features and corpus characteristics influence the identification of authorial style.
Detecting Small Worlds in a Corpus of Thousands of Theater Plays
- Designed for: scholars and students with basic knowledge of network theory
- Topics: typology of theatre plays from a network perspective
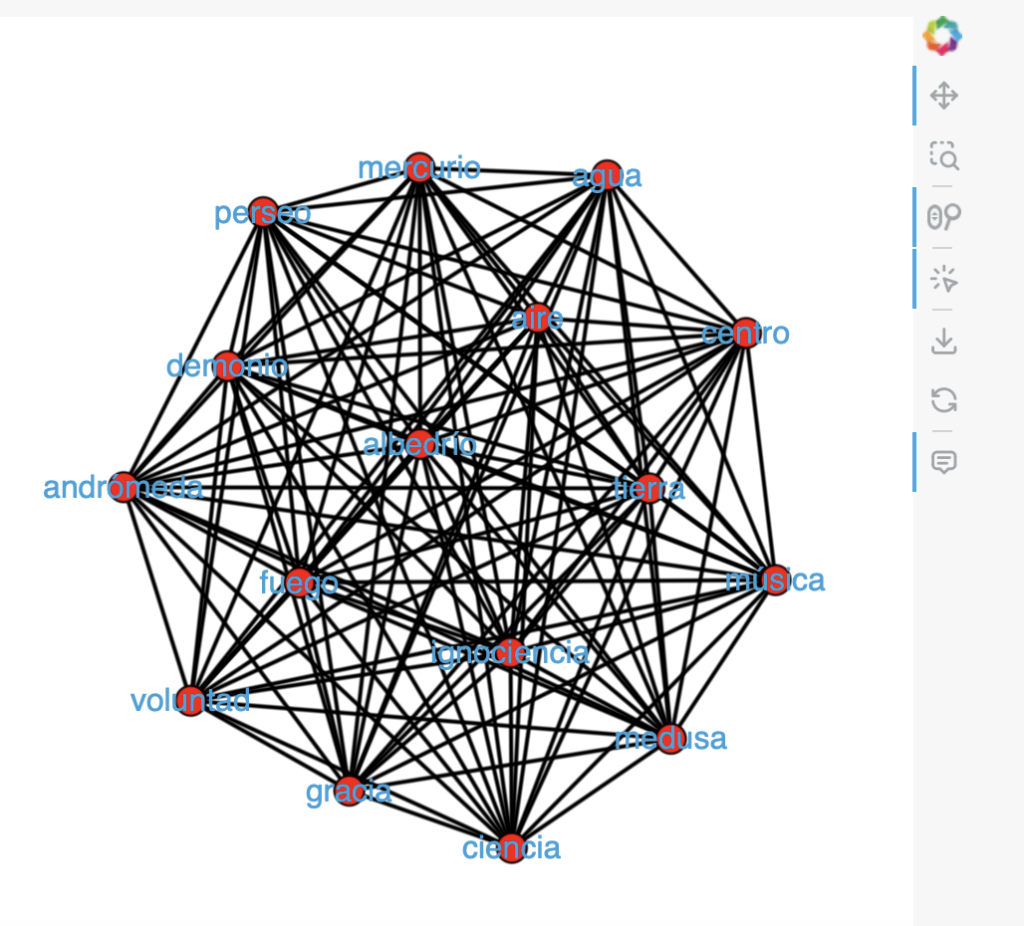
- Dataset: VeBiDraCor – the “very big drama corpus” created by aggregating all individual corpora available on DraCor 9 Aug 2022.
With platforms like DraCor, homogenized TEI corpora of theater plays from different languages are becoming more and more available. This enables a specific approach of comparative study which is based on the method of formal network analysis and its modeling of texts as semantic structures. In this showcase, we take the “Small World” concept from general network theory and try to identify “Small World”-structured texts in a huge multilingual corpus of almost 3,000 plays.
Averell: A corpus management tool to transform poetic corpora into a JSON format compliant with the POSTDATA ontology (Poetrylab Suite, part 1)
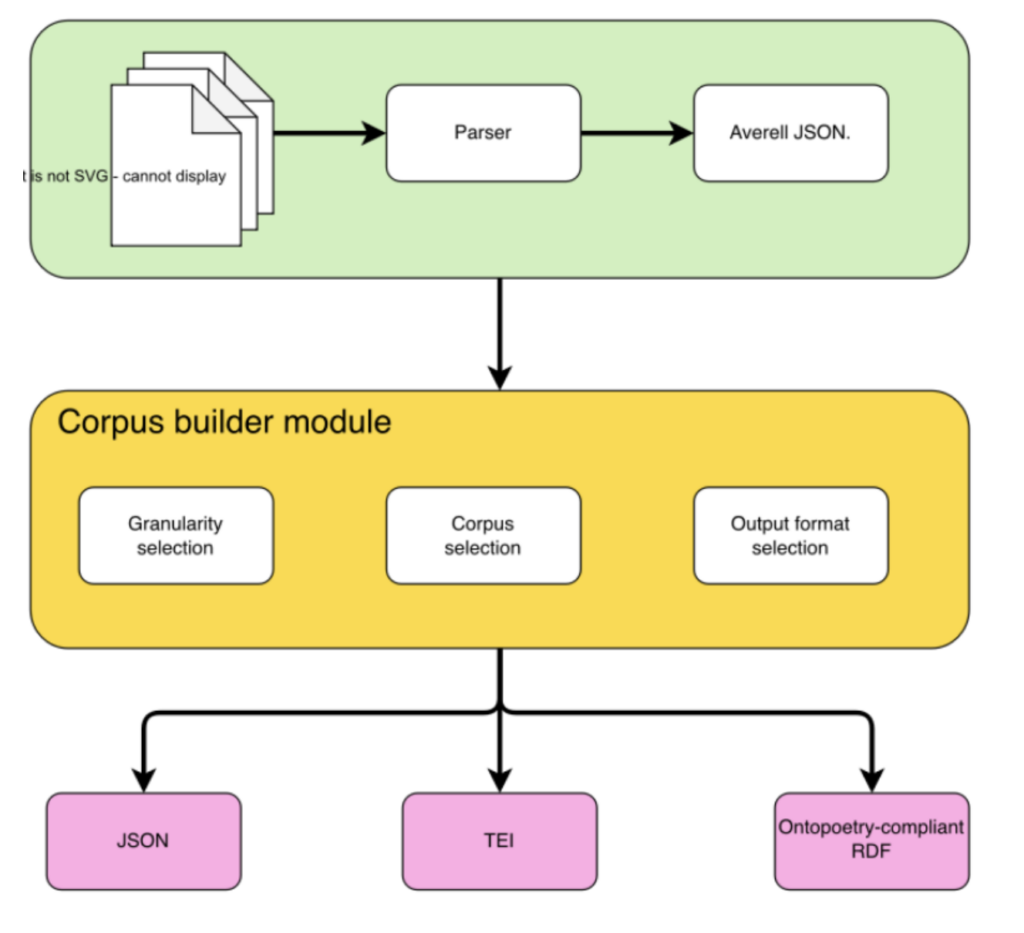
- Designed for: scholars and students interested in poetry
- Function: to help scholars create their own corpora of poetry by merging different corpora together
Averell is a tool that tries to lower the barrier for researchers interested in the study of multilingual poetry corpora. It provides a unified interface to query, manage, download, and merge corpora of poetic nature in multiple languages based on features relevant for poetry scansion and meter analysis.
Poetrylab + rantanplan: Using rantanplan for accurate scansion analysis and visualization (Poetrylab Suite, part 2)
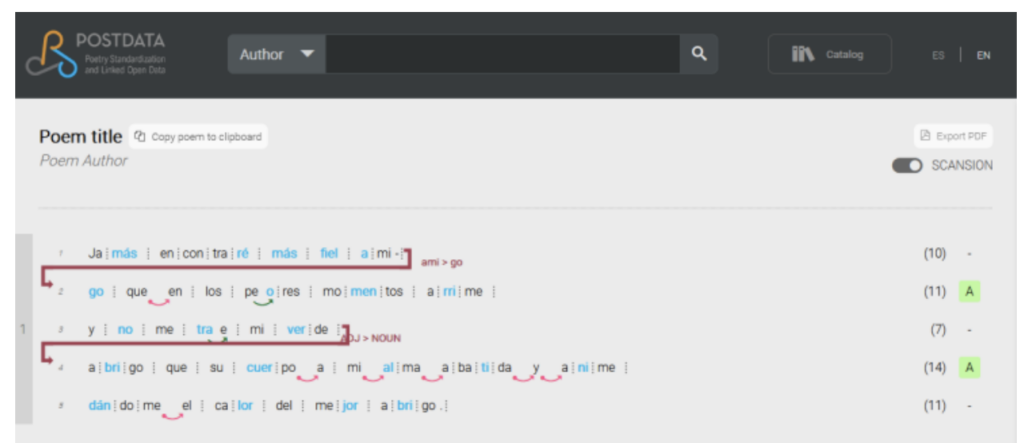
- Designed for: scholars, researchers in linguistics, literature, and culture, poetry enthusiasts
- Topics: Spanish poetic forms
- Function: explore the nuances of meter, rhyme, and structure within various literary traditions of Spanish poetry
Poetrylab presents a suite of tools for the analysis and visualization of Spanish poetry. This comprehensive platform is designed to cater to a diverse audience, including scholars, researchers, students, and poetry enthusiasts. At the heart of Poetrylab lies rantanplan, a specialized Python library meticulously crafted for the scansion of Spanish poems. Leveraging advanced computational linguistics algorithms, rantanplan facilitates the identification and categorization of syllabic patterns, meter, and rhythmic structures within Spanish poetic compositions. Users can engage with Poetrylab’s user-friendly interface to conduct detailed scansion analyses, gaining valuable insights into the metrical intricacies and poetic nuances of Spanish verse. Whether exploring established literary traditions, studying poetic techniques, or seeking inspiration for creative endeavors, Poetrylab serves as an invaluable resource, fostering deeper understanding and appreciation of Spanish poetry among its users.
CLS INFRA TNA Fellow Jana Mende
In this video, CLS INFRA TNA Fellow Jana Mende (Martin-Luther-Universität Halle-Wittenberg) speaks about the project: ‘Monolingualism Deconstructed: Modelling Hidden and Invisible Multilingualism in German literature (1790-1890)’
CLS INFRA TNA Fellow Haimo Stiemer
Seminar: The Clash of the Modernists
For a long time, literary journals played only a minor role in book-centred philologies. Since their mass digitisation in the early 2000s, however, this has changed. Using the example of two German-language journals from the first half of the 20th century, this talk will demonstrate the heuristic potential of computational philology working with literary journals. As field artefacts, not only the content but also the form of the journals will be considered. According to Pierre Bourdieu, the form finally has its own message with which the actors position themselves in the world of literature and fight against each other.
Haimo Stiemer was a CLS Infrastructure Fellow at the Moore Institute, University of Galway, and works as a research associate at the Technical University of Darmstadt. Beside Computational Literary Studies, his areas of research include the literature of German-language modernism, Literary Sociology and Theory.
TNA Review video
In this video, CLS INFRA TNA Fellow Haimo Stiemer speaks about the project: ‘The clash of the modernists – Comparing the expressionist journal “Der Sturm” and the journal “Der Querschnitt” from the Weimar Republic’
CLS INFRA TNA Fellow Ewa Data-Bukowska
In this video interview, Round 5 CLS INFRA TNA Fellow Ewa Data-Bukowska (Jagiellonian University, Krakow, Poland) speaks about the project: ‘Language use in the paradigm of sustainability: Swedish translations of the works of Witold Gombrowicz’.
CLS INFRA TNA Fellow Eduardo Fernández
In this video interview, Round 4 CLS INFRA TNA Fellow Eduardo Fernández (European University Institute, Italy) speaks about the project: ‘Distant reading of early modern prophecies across Europe: corpus formation and testing’.
Cls Infra TNA Fellow Maciej Maryl
This seminar by Maciej Maryl was produced at the Moore Institute, University of Galway, 13 Dec 2023. It includes a presentation and discussion around the recent ALLEA report Recognising Digital Scholarly Outputs in the Humanities, which underscores the transformative impact of digital practices on humanities scholarship. It addresses challenges in digital humanities, focusing on transparency in linking resources to publications, recognising updates as scholarly contributions, reevaluating authorship, fostering digital skills, and adjusting evaluation methods. It also provides recommendations on the assessment of digital outputs like editions, databases, infographics, code, blogs, and podcasts. Each case study includes practical examples and suggested readings.
In this video, CLS INFRA TNA Fellow Assistant Professor Maciej Maryl speaks about the project: ‘Social Network Analysis of Career Trajectories in Polish Literature after 1989’
CLS INFRA TNA Fellow Richard Změlík
In this video interview, Round 3 TNA Fellow Richard Změlík discusses the project “Building a Literary Corpus of 19th Century Czech Prose’
D6.3 Standards beyond TEI / Extended Transformation Matrix / Alternative Formats
This deliverable builds on and further extends the findings of D6.1 “Inventory of existing data sources and formats” surveying the landscape of literary corpora, as well as D8.1 “Tools for NLP” cataloguing the set of tools in the context of CLS. Focusing on the wealth of formats used when encoding and processing text, it offers a comprehensive overview of common formats for encoding textual data, beyond the “lingua franca”, TEI, both in the domain of computational literary studies and computational linguistics, highlighting potential discrepancies in the approach between these two areas of research. The overview reveals a very heterogeneous landscape with a plethora of formats, devised for differing tasks, from philological encoding of historical text material, to computational annotation and processing of text.
Considering interoperability an indispensable key to reusability, the deliverable explores the challenges and approaches converting between formats.

CLS Beyond academic research: Interviews for Task 3.5
Dr Jennifer Edmond (Trinity College Dublin and DARIAH-EU) and Vera Yakupova (CLS INFRA and Trinity College Dublin) discuss the result of their interviews with non-academics on current and potential uses of Computational Literary Studies tools in the fields of:
- Policy
- Consultancy
- Journalism
- Medicine/ Psychology
- Publishing
- Arts
More will arise from this task – watch this space! If you are working in these fields and would like more information, contact us.
D5.2 Case Studies in Data Preparation and Sharing
Building on previous CLS INFRA deliverables, this report provides step-by-step case studies of research questions involving digitisation and transformation processes of literary corpora. The case studies:
- Creation of an ELTeC affine corpus of the Slovak novel (chapter 2)
- Finding the haiku across multilingual corpora (chapter 3)
- Measuring entropy and surprisal in the prose of the Tsarist Empire Devoted to Terrorism (Russian and Polish Texts) (chapter 4)
These case studies uniquely address not only the tools and resources available to CLS researchers but the complexities of collaborative decision-making regarding research methodologies.

D8.1: Tools for Basic Natural Language Processing (NLP) Tasks
In this video, Prof. Dr. Julie Birkholz and Mgr. Dr. Silvie Cinková discuss D8.1. This report lists and describes a selection of Natural Language Processing (NLP) tools which are considered to form a Corpus-Enrichment and NLP toolchain for common CLS research tasks. The tools were selected to be:
- safely positioned in their life cycle, i.e., state-of-the art, and mature as well as continuously maintained, or in development and promised as CLS Infra Deliverables by March 2025
- as multilingual as possible (beyond English and several major European languages)
- as interoperable as possible with other tools and texts in other languages.
D3.2: Survey of Methods
This survey documents current, widespread practices in research areas or issues that are prominent within CLS. Though it is not intended as a primer, the Survey Grid provides useful, targeted information in a format suitable for gaining a broad understanding of methods and issues. Fields include authorship attribution, genre analysis, literary history, gender analysis, and canonicity.
Click here to use the Survey Grid and review the deliverable.

CLS INFRA TNA FELLOW Khanim Garayeva
In this video CLS INFRA TNA Fellow, Khanim Garayeva, speaks about the project: ‘Calculations of similarities or distances in Peter Ackroyd’s historiographic metafictions and lexical diversity in Dan Brown’s straightforward storytelling’.
TNA ARCHIVES
The CLS INFRA Transnational Access Fellowship Programme funds scholars from literary studies or with an interest in Computational Literary Studies methods to visit leading research institutions and infrastructures and become part of the larger CLS community.
This archive includes interviews with the TNA Fellows on their experience, their research project and outcomes, video testimonials produced during their fellowship and access to their full reports. Check out the archives here.

D7.1: On programmable Corpora and DraCor
Work Package 7 of the CLS project, entitled “Building the Ecosystem of and for Programmable Corpora”, is developing a small-scale, but highly functional prototype for an infrastructural ecosystem for CLS research, following the concept of a network-based software architecture. The prototype, implemented as the multi-component system “DraCor” (Drama Corpora Platform), realizes the concept of “Programmable Corpora”, which is defined as corpora that expose an open, transparently documented and (at least partly) research-driven API to make texts machine-actionable. This report gives a detailed description of the DraCor system as a prototype for “Programmable Corpora”. It also shares two first experiments in adapting and transferring the approach of an API-based CLS research infrastructure to other systems and resources.
The first stable version of the DraCor API (1.0.0) was released in December 2023, marking a significant milestone in the system’s development. Watch this space for more announcements!
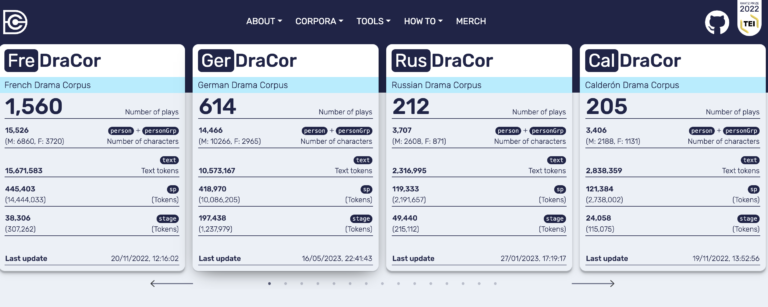
DraCor: Drama Corpora Project. Click logo for link.
CLS INFRA TNA Fellow Cassandra Ulph
In this video CLS INFRA TNA Fellow, Dr Cassandra Ulph, speaks about her project:’Developing Attribute-based Sentiment Analysis Model for Romantic-period Letters’.
CLS INFRA TNA Fellow Federico Pianzola
In this video CLS INFRA TransNational Access Fellow, Assistant Professor Federico Pianzola, speaks about the project: ‘Programmable Corpora as Linked Data’.
Training School: Madrid
From 9-11 May 2023, CLS INFRA offered a crash course in how to “Dig for Gold” in a corpus of texts. From Stylometry to Natural Language Processing, participants completed their own analyses and visualisations of the results in a hands-on way. We worked with existing code that is plug and play, so it was not necessary to have existing experience in Python or R. Most of all, it was a fun and safe environment to boost textual analysis skills.
Training materials are available on DARIAH CAMPUS. Click the button below.

CLS INFRA TNA FELLOW Ivan Pozdniakov
In this video CLS INFRA TNA Fellow, Ivan Pozdniakov, speaks about his project: ‘Building an R Package and Web Application to Interact Within a Digital Ecosystem for Literary Studies’.
Deliverable 5.1 Review of the Data Landscape
In this video PD Dr. Michal Mrulgaski summarises CLS INFRA Deliverable 5.1 ‘Review of the Data Landscape’. This landscape review focuses on intellectual access, i.e. providing guidance for finding and sharing literary data, while D6.1 approaches the task from a more technological side, collecting and analyzing literary corpora, available formats, tools, and metadata in order to create an exploratory catalogue / inventory of literary corpora and to provide a transformation matrix/toolbox for solving common issues. Yet we coordinate our efforts – beginning with the compilation of the table of literary collections – therefore one can regard these as two sides of the same coin. The review’s point of departure is the abundance of existing data and their diversity or heterogeneity as regards corpus design and underlying concepts, for example the definitions of text (is it a source, an edition, a data set? see chapter 3), the purpose of a corpus (e.g. general, reference, or monitoring corpora, special purpose corpora; see chapter 4), central considerations or criteria regarding the construction of a corpus (sampling, balancing, representativeness, annotation model(s), data format(s); see likewise chapter 4). How can I go about obtaining data without transgressing ethical or legal boundaries (see chapter 5)? We ask: How can we assist literary scholars in searching for and finding existing data that are relevant to their own research questions? And additionally, what kind of research question is relevant concerning the present-day state of the data landscape and literariness and textuality?
Srishti Sharma - Can a Book Make You Happy?
On Wednesday 29 June Srishti Sharma presented the results of her fellowship as a Transnational Access Research Fellow on the H2020 Computational Literary Studies project at GhentCDH. Her research project explores the effect of the emotions expressed in fictional novels on the emotions experienced by their readers. The corpus includes more than 400 English books from 9 different genres and their corresponding reviews from the Goodreads platform. Using sentiment analysis and emotion recognition she seeks to investigate the emotional links between genre, plot, and reader response.
CLS INFRA TNA FELLOW SRISHTI SHARMA
In this video CLS INFRA TNA Fellow, Srishti Sharma, speaks about her project ‘Can A Book Make You Happy?’ which is being hosted at Ghent University.
CLS infra tna fellow Riva quiroga
In this video CLS INFRA TNA Fellow, Riva Quiroga, speaks about her ‘Improving Part of Speech Tagging for Latin-American Spanish Corpora’ project which is being hosted at Charles University, Prague.
Cls Infra TNA Fellow Lou Burnard
In this video CLS INFRA TNA Fellow, Lou Burnard, speaks about his ‘Reviving the Victorian Play’s Project’, which is being hosted by the Moore Institute at NUI Galway, Ireland.
Deliverable 4.1: Skills gap analysis
We have explored gaps in teaching of research skills for computational literary studies to inform the CLS INFRA project’s own approach to training schools and chart the territory to gain broader insight into current CLS teaching practices. To understand supply we have manually annotated a sample of European university courses in Digital Humanities and summer school workshops. To index demand we set up an online survey to ask the community to evaluate a set of predetermined ‘skills’ based on its perceived future prospects in the field and teaching (1-5 scale response, 118 participants).
The survey also offered a chance to observe the demographic structure of the CLS community. The prevalence of early career respondents indicates a new generational wave within computational literary studies. Participant gender was balanced, although introduction of variables such as career stage, self-reported proficiency, and discipline demonstrated skewness. Researchers who work in the field of CLS also report more experience in computational methods, which suggests that these go hand in hand in current practice. Despite the gap in skills education being more general in nature, we identified areas of heightened interest. These are the skills that make up the backbone of computational research: from designing the study to text collection, to multivariate analysis and statistical modeling. Survey responses reiterated that the current gap in schooling is quantitative rather than qualitative. Moreover, there was a consensus among participants that the institutionalized training of a new generation of researchers is instrumental to disciplinary advancement of CLS.
Deliverable 3.1: Baseline Methodological User Needs Analysis
The purpose of this task was to identify, document and show-case best practices in CLS research in order to specify infrastructure requirements for the community. The central concerns of our study are data formats, tools and methods most widely mentioned in the publications related to CLS. These findings play an important role also for the training programme within the project, as they show what key qualifications are required for literary studies, what data formats researchers deal with and what methods and tools are especially relevant in the CLS field.
- Download and read this report here.
- Watch a summary of the findings on our YouTube channel.
Training School: Prague
The training school on Data and Annotation took place from 7 to 9 June 2022 and be hosted by the Institute of Formal and Applied Linguistics of the Faculty of Mathematics and Physics, Charles University in Prague, Czechia.

The materials, videos of sessions, and other information can be found on the DARIAH campus.
KRAKÓW DH LUNCH: THE CLS INFRA PROJECT
CLS INFRA Principal Investigator, Professor Maciej Eder (IJP PAN) gives a quick tour around the CLS INFRA project for computational literary studies at the Kraków DH Lunch on 11th February 2022.
This special DH lunch introduces the Computational Literary Studies Infrastructure (CLS Infra) project – a multinational European collaboration to connect people, data, tools, and methods, focused on large-scale analysis of literary sources.
D4.1 SKILLS MATRIX SURVEY
This survey is being completed as part of Deliverable 4.1 ‘Report on the Skills Matrix and Gap Analysis’ and aims to find out which areas of research the research community would like to see represented in learning the computational and research skills necessary for data-driven studies of literature. The results of this survey will be used to supplement the current offer in training and schooling with a series of Training Schools. The first CLS INFRA Training School took place in Prague from 7-9 June 2022 on the topic of Data and Annotation.
Researcher profile: Professor Maciej Eder (PI)
In this video, our project’s Principal Investigator Professor Maciej Eder introduces us to the CLS INFRA project and how Computational Literary Studies methodologies and research intersect with his own scholarship and teaching. Make sure to subscribe to our YouTube channel so that you don’t miss our upcoming researcher profiles.
Views: 5,582